x87 FPU で厳密な単精度演算を行うコスト
senna_hppの日記より.
DirectXから入ったので、浮動小数点演算にはfloat型演算を使うようになったのですが、実際にはdouble型の方が速いそうなのでその確認のための検証実験。
(中略)
type add(ms) sub(ms) multi(ms) div(ms) double 203.6 201.9 5.6 5.4 flaot 913.4 912.9 674.0 675.1 double(template) 201.1 201.3 5.1 5.4 float (template) 913.8 915.0 680.2 675.5 double(template specialization) 201.7 201.5 6.5 4.7 float(template specialization) 913.6 912.2 674.0 674.2 結果としてはdouble型が完全勝利と言えるでしょう。
ただし、PS2などはfloat型演算の方が速いので、処理系やコンパイラによって常にこのような結果になるとは限りません。
試しに手元の Visual Studio 2005 でもコンパイルさせてみましたが,ディスアセンブル結果を見てると,何となく状況が読めてきたり.Release ビルドのデフォルト値から想像するに,恐らくコンパイルオプションの「浮動小数点モデル」が「Precise (/fp:precise)」になっているのかと思います.
// double 版 (速い) for(int i=0;i<N;++i) a1 += a2; 00401069 sub eax,1 0040106C fadd st(3),st 0040106E fadd st(2),st 00401070 fadd st(1),st 00401072 fadd st(3),st 00401074 fadd st(2),st 00401076 fadd st(1),st 00401078 fadd st(3),st 0040107A fadd st(2),st 0040107C fadd st(1),st 0040107E fadd st(3),st 00401080 fadd st(2),st 00401082 fadd st(1),st // float 版 (遅い) for(int i=0;i<N;++i) a1 += a2; 004013AD fld dword ptr [esp+20h] 004013B1 fadd st,st(1) 004013B3 fstp dword ptr [esp+20h] 004013B7 fld dword ptr [esp+24h] 004013BB fadd st,st(1) 004013BD fstp dword ptr [esp+24h] 004013C1 fld dword ptr [esp+28h] 004013C5 fadd st,st(1) 004013C7 fstp dword ptr [esp+28h] 004013CB fld dword ptr [esp+20h] 004013CF fadd st,st(1) 004013D1 fstp dword ptr [esp+20h] 004013D5 fld dword ptr [esp+24h] 004013D9 fadd st,st(1) 004013DB fstp dword ptr [esp+24h] 004013DF fld dword ptr [esp+28h]
詳細については以前の日記や例の記事で書いたので省略しますが,問題の float 版では,連続して fadd していくと指数部が 80-bit 精度で計算され続けてしまうため,毎回メモリに書き出して読み直すことで単精度での完全丸めを行っているようです*1.
見るからに悲惨ですが,こうやってパフォーマンス差と一緒に見せられると確かにインパクトありますねぇ.
ちなみにこのテストコードで「浮動小数点モデル」を「Fast (/fp:fast)」にすると,概ね float の方が速いという結果になるようです*2.
CodeZine の記事用に作ったけど結局使わなかった図もついでに貼ってみたり.
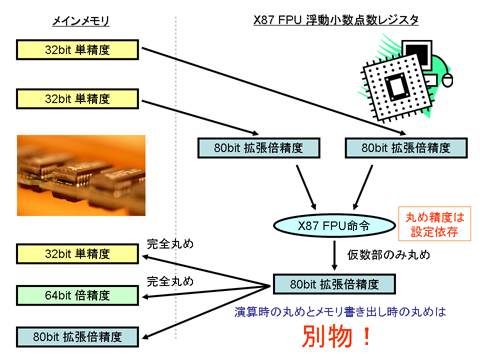
*1:store-reload で FP-strict な単精度演算が実現できることについては,首藤氏の『厳密な浮動小数点演算セマンティクスの Java 実行時コンパイラへの実装』参照のこと
*2:追記.とはいえほとんど差はない