ValueType.Equals のオーバーライド,ReSharper 3.0,partial type
値型のデフォルトの Equals メソッド,すなわち ValueType.Equals は,リフレクションを使用して各フィールドの Equals メソッドを順番に呼び出すため,パフォーマンス上不利になることがあります*1.
Equals メソッドの既定の実装では、リフレクションを使用して、obj の対応するフィールドとこのインスタンスを比較します。メソッドのパフォーマンスを向上し、その型の等価性の概念をより厳密に表現するには、特定の型の Equals メソッドをオーバーライドします。
XNA プログラミングでは,軽量なデータレコードとして値型を多用するのですが,特に何度も使い回す基本的な型については後で利用することを考えてこのあたりのコードの整備もやっておいた方が良いでしょう.さらに言えば,Generics が導入された .NET 2.0 以降では,IEquatable<T> を実装するのが一般的でしょう.こうすれば,ValueType.Equals (object other) のオーバーライド,== 演算子と != 演算子のオーバーロードは,厳密に型指定された IEquatable<T>.Equals (T other) を内部で呼び出すことで事足ります.さらに ValueTyoe.GetHashCode メソッドのオーバーライドも,等価性を満たすように調整しておきましょう.もちろん Microsoft.Xna.Framework.Vector2 など,XNA Framework の型はきちんとこの作業を行っています.
さて,あるフィールドが確定した構造体があるときに,型指定された等価性判定コードを作成するのは,手作業で行えば面倒な作業ですが,幸い ReSharper のコード生成機能で自動化することができます.ちなみにバージョン 3.0 でやっと IEquatable<T> を意識したコードを出力してくれるようになるようです.
例えば次のような構造体を考えてみます.
public struct Vector2 { public double X; public double Y; }
この構造体に,ReSharper 3.0 beta のコード生成機能から,"Equals and GetHashCode" を適用してみます.すると,次のようなダイアログが表示されます.
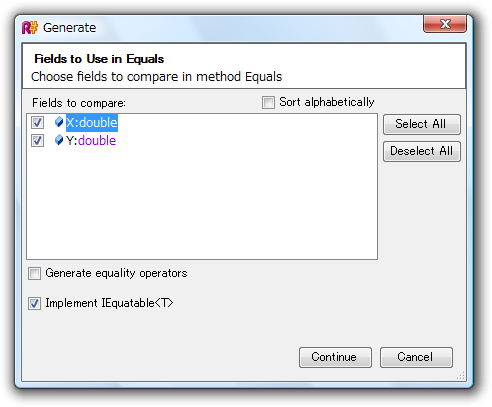
等価性の評価と GetHashCode の計算に使用するフィールドを選ぶと,以下のようにコードが自動生成されます.
public struct Vector2 : IEquatable<Vector2> { public double X; public double Y; public static bool operator !=(Vector2 vector21, Vector2 vector22) { return !vector21.Equals(vector22); } public static bool operator ==(Vector2 vector21, Vector2 vector22) { return vector21.Equals(vector22); } public bool Equals(Vector2 vector2) { return X == vector2.X && Y == vector2.Y; } public override bool Equals(object obj) { if (!(obj is Vector2)) return false; return Equals((Vector2) obj); } public override int GetHashCode() { return X.GetHashCode() + 29*Y.GetHashCode(); } }
さて,ReSharper 生成したコードに特に不満があるわけではありませんが,せっかくシンプルだった構造体定義がずいぶんと縦に広がってしまいました.もちろん #region キーワードで折りたたんでしまうこともできますが,ここでは partial type を使用して IEquatable<T> がらみの実装を分離してみましょう.
public partial struct Vector2 { public double X; public double Y; }
public partial struct Vector2 : IEquatable<Vector2> { public static bool operator !=(Vector2 vector21, Vector2 vector22) { return !vector21.Equals(vector22); } public static bool operator ==(Vector2 vector21, Vector2 vector22) { return vector21.Equals(vector22); } public bool Equals(Vector2 vector2) { return X == vector2.X && Y == vector2.Y; } public override bool Equals(object obj) { if (!(obj is Vector2)) return false; return Equals((Vector2) obj); } public override int GetHashCode() { return X.GetHashCode() + 29*Y.GetHashCode(); } }
とまあ分けることに意味があるのかはとにかく,こういう分離自体は可能です.partial type のおもしろいところは,このように,インターフェイスや属性の和集合が実際に合成される型に適用されるところです.なんと基底クラスの宣言も合成されます.もっとも,.NET では基底クラスは 1 つしか持てませんが.
partial type はどうも気に入らない,という人の気持ちも分からないではないですが,安定部分を記述したソースコードのリビジョンをあげずに,プロジェクトに参加するファイルを付け外しするだけで実装を注入できるという点ではなかなかおもしろい機能と言えるのではないでしょうか.
*1:ただ,すべてのフィールドがプリミティブ型の場合など,特定条件では高速なメモリ比較で済ませられていたような気がしなくもないです.